Slik klassifiserer Oslo Universitetssykehus denne genetiske varianten:
Variant: NM_003688.3:c.2603A>G
ACMG-klassifisering: 3* - variant av usikker betydning
*i henhold til kriterier PP3+PM2 som definert i Richards S et al. 2015 Genet Med 17:405

"Fortolkede genetiske varianter er i seg selv anonyme"
Slik klassifiserer Oslo Universitetssykehus denne genetiske varianten:
Variant: NM_003688.3:c.2603A>G
ACMG-klassifisering: 3* - variant av usikker betydning
*i henhold til kriterier PP3+PM2 som definert i Richards S et al. 2015 Genet Med 17:405
Tolkning av genetiske varianter er et område som er i stadig utvikling etterhvert som ny kunnskap kommer til. For å lære av hverandre og fange opp eventuelle avvikende vurderinger er det viktig at ulike kliniske miljøer kan dele med hverandre hvordan de klassifiserer en genetisk variant. Frem til i dag har dette ikke vært gjort ved Oslo Universitetssykehus, da den juridiske problemstillingen knyttet til personvern og anonymitet har vært uavklart. Fordi genetisk informasjon er definert som særlig sensitiv informasjon har man i Norge ofte lagt seg på en forsiktig linje. BigMed-prosjektet har gjennomført en juridisk vurdering av hvorvidt en fortolket enkeltstående genetisk variant kan anses som anonym og dermed deles fritt, og konkluderer med at ja – det er den.
I BigMed-prosjektet er det foretatt en vurdering av om fortolkede genetiske varianter er anonyme og hvordan grensen mellom anonyme og personidentifiserbare genetiske opplysninger kan trekkes (1). Fortolkede genetiske varianter kalles også klassifiserte genetiske varianter, da de er vurdert etter bestemte faglige kriterier. I dette notatet gis det en kortfattet oppsummering av konklusjonene og grunnlaget for konklusjonene.
Utfordringen med genetiske data er at de i større utstrekning kan føre til identifisering av den opplysningene kommer fra. Samtidig er det variasjon når det gjelder mulighetene for identifisering og dataenes sensitivitet. For å ta stilling til om en fortolket genetisk variant er anonym og hvordan grensen mellom anonyme og personlige genetiske data kan trekkes, må det vurderes hvordan gjeldende rett kan fastlegges på bakgrunn av relevante rettskilder og argumenter.
Den første problemsstillingen er om det er mulig å føre de fortolkede genetiske variantene tilbake til en person eller om de er garantert anonyme (objektiv anonymitet). Dersom svaret er at varianten ikke kan føres tilbake til en person er spørsmålet om de likevel kan identifisere en person dersom antallet forekomster av de genetiske variantene er få (forekomstidentifisering) (2). Dersom det er mulig å koble genetiske varianter til en person må det vurderes om de likevel er anonyme som en følge av at det er lav risiko for identifisering (risikobasert anonymitet). Det er aktuelt å vurdere hvilken betydning forsiktighetshensyn kan tillegges ved behandling av genetiske varianter og opplysninger til helsehjelp og helseforskning. Usikkerhet om mulighetene for identifisering og om fremtidig teknologi kan være et argument for at det innhentes samtykke til å behandle genetiske data.
Konklusjonen er at en fortolket genetisk variant er anonym forutsatt at den ikke gis sammen med annen personidentifiserbar informasjon. Antallet forekomster av genetiske varianter i befolkningen, i likhet med forekomsten av avvik i hvordan et hjerte eller en hjerne er sammensatt, er ikke avgjørende for grensen mellom anonyme data og personopplysninger, eller for hvordan genetisk og medisinsk kunnskap deles. Utbredelsen av genetiske varianter gir ikke tilstrekkelig risiko for identifisering.
Dersom fortolkede genetiske varianter kan identifisere en person, for eksempel som en konsekvens av at det gis annen informasjon, må det vurderes om dataene likevel er anonyme fordi det er lav risiko for slik identifisering. Risikobasert anonymitet baseres på en dynamisk vurdering av sannsynligheten for at dataene blir knyttet til en person der både mengde og hjelpemidler har betydning. Relevante momenter er tilgjengeligheten til teknisk utstyr, kostnader, kjennetegn ved dataene som behandles, hvordan de filtreres og behandles (kontekst og mengde) og tilgangskontroll (3).
Ved usikkerhet om risikoen for identifisering er tilstrekkelig lav, kan forsiktighetshensyn begrunne at virkninger av å behandle dataene som personopplysninger vurderes, handlingsalternativer og eventuelt virkninger av at dataene ikke kan behandles (forholdsmessighetsvurderinger).
Rettsvirkningene av at en fortolket genetisk variant regnes som anonym er at den kan benyttes uten at den omfattes av reguleringer av personopplysninger. Et laboratorium kan dele fortolkede genetiske varianter og annen informasjon i tilknytning til varianten når det er lite sannsynlig at personen vil bli identifisert på bakgrunn av de totale opplysningene som gis.
En fortolket (klassifisert) genetisk variant er en beskrivelse av hvordan den genetiske varianten antas å fungere og en medisinsk fortolkning av hvilke konsekvenser varianten kan ha for mennesket. Det må velges ut hvilke varianter som må vurderes nærmere, omtalt som filtrering, etter kriterier for hvordan denne utvelgelsen skal foregå (4). Den genetiske varianten sammenlignes med referansegenomet, det vil si gjennom å vise til likheter og forskjeller (5). Referansegenomet er i all hovedsak identisk med det genomet som ble kartlagt i det humane genomprosjektet (6). Referansegenomet omtales som et standardisert koordinatsystem sammensatt av genetiske varianter.
Genomet er hele arveanlegget (DNA) og omkring 3 milliarder baser (nukleotider) som utgjør de kjemiske grunnenhetene i DNA-molekylene og forekommer i fire forskjellige varianter forenklet beskrevet med bokstavene A, G, C og T (7). Sammensetningen og rekkefølgen på basene bestemmer menneskers arvelige egenskaper (8).
Det å fortolke en genetisk variant innebærer at varianten klassifiseres som sykdomsgivende (sikker patologisk) eller ikke i en skala fra 1 til 5, der 1 = sikker normalvariant som ikke gir sykdom og 5 = sikker sykdomsgivende. Varianter med usikker betydning, såkalte VUS, plasseres i klasse 3. Dersom denne klassifiseringen av forskjellige varianter lagres, kan kunnskapen være tilgjengelig når samme variant påvises hos en ny pasient. På denne måten kan medisinske laboratorier over tid opparbeide seg økt kunnskap om genetiske varianter og deres betydning for sykdom og behandling. Sammenligning med andre laboratoriers klassifisering av varianter er viktig for å kunne kvalitetssikre variantklassifiseringen. Det er en erkjent utfordring for pasientsikkerheten at ulike laboratorier noen ganger klassifiserer varianter forskjellig og at dette kan få alvorlige konsekvenser for pasienter gjennom uriktige diagnoser og medisinsk behandling (9).
Kunnskapen vil bli mer sikker etter hvert som evidensmaterialet øker for den enkelte variant. Dette har stor betydning for å oppnå økt genetisk kunnskap som på sikt vil bidra til raskere og riktigere diagnoser og behandling. Det humane genom og genetiske varianter endres over tid gjennom mutasjoner som kan beskrives som evolusjon og tilpasning. Det innebærer at nye genetiske varianter oppstår og at antallet variasjoner øker (10).
En fortolket genetisk variant kan beskrives som et genetisk funn og som ny medisinsk kunnskap. Denne kunnskapen kan likestilles med annen medisinsk kunnskap om hva som gir andre sykdomstilstander, blant annet beskrevet slik:
«A link between a particular genetic variant and clinical features of a disease is not personal information any more than the link between high blood cholesterol and heart disease.» (11)
Innenfor medisinsk vitenskap beskrives biologiske forutsetninger og sykdomstegn, i likhet med genetiske disposisjoner, som medisinsk kunnskap i vitenskapelige artikler, lærebøker og på internett. Medisinsk kunnskap skal deles for at andre mennesker kan nyte godt av denne kunnskapen. De rettslige utfordringene oppstår når genetiske data som er medisinsk kunnskap også kan være personopplysninger.
Taushetsplikten omtales i forarbeidene til personopplysningsloven som en «garanti» for å beskytte opplysninger fra pasienter og forsøkspersoners integritet (12). Taushetsplikten kan både gi grunnlag for et vern av opplysninger og kilden til opplysninger, men er tilpasset behovet for å dele opplysninger for å ivareta mulighetene for forsvarlig helsehjelp og helseforskning (13). Denne plikten gjelder ikke for de som allerede har kjennskap til hvem de genetiske variantene tilhører eller når personens identitet er tilstrekkelig beskyttet.
Personvernforordningen (GDPR) er inkorporert i personopplysningsloven § 1 (14).Grensen mellom anonyme og personlige genetiske opplysninger trekkes i all hovedsak gjennom hvordan legaldefinisjonen av personopplysninger, helseopplysninger og genetic data i GDPR, kan fastlegges. Legaldefinisjonen av personopplysninger i GDPR art. 4 (1) og fortolkninger av denne bestemmelsen utgjør en felles kjerne for definisjonene av genetic data og health data i henholdsvis art. 4 (13) og (15). I helselovene er det henvist til definisjonen i GDPR art. 4 (15), se pasientjournalloven (pjl.) § 2 b, helseregisterloven (hregl.) § 2 b og helseforskningsloven § 4 d (15).
En konsekvens av at genetiske data omfattes av legaldefinisjonene er at minst ett av vilkårene i forordningen art. 6 (1) og i art. 9 (2) må være oppfylt. I begge bestemmelsene er det henvisning til nasjonal lov. Ved anvendelse av genetiske data i helsehjelp er det unntak i GDPR art. 9 (2) h og (3). Det innebærer at helsepersonelloven, pasient- og brukerrettighetsloven, pasientjournalloven, spesialisthelsetjenesteloven og helseforskningsloven, kommer til anvendelse (16).
Et overordnet krav er at menneskers verdighet skal ivaretas, det vil si menneskerettigheter som ligger til grunn for integritetsvernet i lovgivningen og personvernforordningen. Menneskerettighetene fremgår både av grunnloven, lovgivningen for øvrig og internasjonale konvensjoner, og omfatter et vern mot diskriminering og mot fysiske krenkelser, inngrep i familie- og privatlivet og ivaretakelse av frivillighet (autonomi) (17). Respekten for menneskeverdet og plikten til forsvarlighet er samtidig argumenter for å få tilgang til data, både anonyme og personlige genetiske data, og for lagring av relevante og nødvendige data (18). Dette begrunner at risikovurderinger må omfatte ulike konsekvenser av hvordan genetiske data behandles og av at de ikke behandles (19).
Den Europeiske Menneskerettighetskonvensjon av 1950 (EMK) og FNs konvensjon om økonomiske sosiale og kulturelle rettigheter av 1960 (ØSK) inneholder flere artikler som er aktuelle ved behandling av genetiske data: EMK art. 2, 3, 8 og 15 og ØSK art. 12. FNs konvensjon om sivile og politiske rettigheter av 1960 inneholder regler om helseforskning og behandling av data, se art. 7 og 17. Disse konvensjonene reguleres av menneskerettighetsloven som bestemmer at de går foran norsk lov ved motstrid (20). Biomedisinkonvensjonen omfattes ikke av menneskerettighetsloven, men inneholder forpliktelser som Norge har sluttet seg til (21).
Forholdet mellom internasjonale menneskerettigheter, GDPR, personopplysningsloven og helselovene kan illustreres slik:
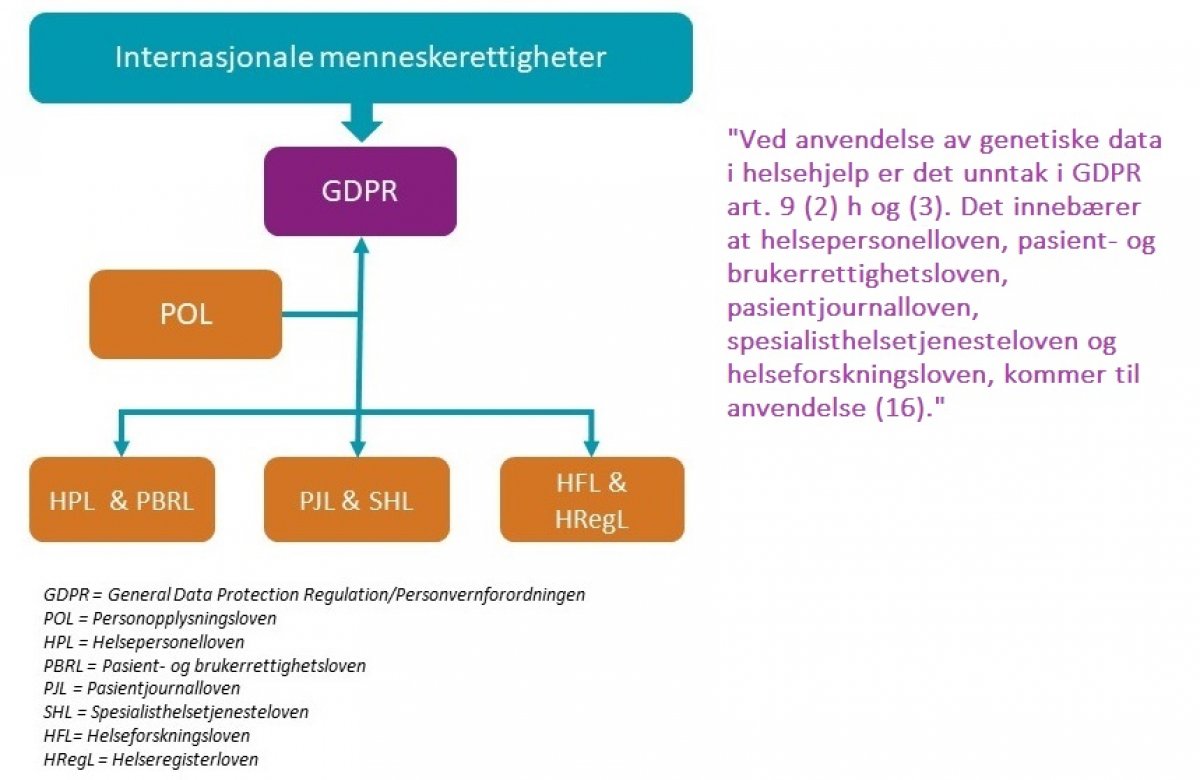
De internasjonale menneskerettighetene er grunnleggende og overordnet både europeisk og nasjonal lovgivning. Dette er grunnleggende og overnasjonale rettigheter som alle mennesker har i kraft av å være menneske. GDPR gjelder derimot i utgangspunktet bare for land innenfor EU/EØS-området og presumeres å være i samsvar med menneskerettighetene. Videre er GDPR en generell forordning for behandling av personopplysninger. Denne generelle forordningen åpner for at medlemslandene kan særregulere behandling av personopplysninger blant annet når formålet er å yte helsehjelp. Norsk helselovgivning er særlovgivning og forutsettes å være i samsvar med både forordningen og internasjonale menneskerettigheter.
Når innføringen av brede genetiske undersøkelser diskuteres vises det til faktiske utfordringer med å garantere forskningsdeltakeres anonymitet med henvisning til at genetikken er unik for den enkelte deltakeren (22). Genetiske data og biologisk materiale kan med avansert teknologi være en kilde til identifisering og omfattende informasjon, men muligheter for identifisering varierer utfra omfang, uttrykk og sensitivitet. Genetiske data kan ikke alltid kobles til en person.
Når genetiske varianter vurderes er et viktig moment at 99 % av alle genetiske varianter er felles mellom mennesker. Når en fortolket genetisk variant finnes hos flere mennesker kan den ikke føres tilbake til ett menneske. En enkelt genetisk variant kan heller ikke betegnes som unik for en person. En fortolket genetisk variant uten andre opplysninger som kan identifisere en person, er anonym med utgangspunkt i en objektiv tilnærming.
Med utgangspunkt i faktiske og rettslige vurderinger vil antallet forekomster av en genetisk variant som hovedregel ikke være avgjørende om en person kan identifiseres. Antallet ganger en fortolket genetisk variant er observert gir ikke informasjon som kan kobles til et bestemt menneske. Dette innebærer at SSBs anonymiseringsprinsipper for behandling av statistikk som ligger åpent og tilgjengelig, ikke kan anvendes ved vurdering av genetiske varianter (23). Dette er ikke mulig å identifisere en person uten tilgang til en oversikt over samtlige genetiske varianter og hvordan disse er fordelt mellom mennesker.
Det må skilles mellom forekomstidentifisering på bakgrunn av frekvens og identifisering på bakgrunn av en større mengde med data som kan omfatte flere genetiske varianter og annen informasjon som gjør det mulig å identifisere en person. Opplysningene kan også i denne situasjonen være anonyme selv om de ikke er objektivt anonyme, på bakgrunn av at det er lav risiko for identifisering (risikobasert anonymitet).
Mulighetene for identifisering øker når et datasett inneholder andre person- og helseopplysninger i tillegg til genetiske opplysninger (24). Det må vurderes når mengden med genetiske varianter og andre opplysninger øker sannsynlighetene for at personen identifiseres. Et utgangspunkt er at færre enn 100 single nucleotide polymorphisms (SNPs) er nok til å skille mellom to individers DNA-profil (25). Summen av mange varianter fra samme individ i ett og samme begrensede sett/database kan føre til et identifiserende «fingeravtrykk». Denne formen for identifisering bygger på tilgang til avanserte hjelpemidler som kan være lite sannsynlige at vil bli anvendt og må ses i sammenheng med hvordan dataene behandles.
Risikovurderinger av mengde må foretas konkret på bakgrunn av hvordan dataene skal behandles og kjennetegn ved dataene (26). Formålet med databasen, tilgangen til innholdet i databasen og tilgangskontroll, samt hvordan opplysninger settes sammen, og utvalget av data kan også ha betydning for om de er anonyme (27). Videre må det vurderes hva som kreves av teknologi for å kunne identifisere genetiske data, for eksempel om den er alminnelig tilgjengelig eller om det er usannsynlig at relevant teknologi vil bli benyttet.
Om flere genetiske varianter lagres fra flere mennesker, kan anonymiteten være opprettholdt dersom sammenhengen mellom dataene er tilstrekkelig beskyttet. Filtreres genetiske data slik at variantene ikke kan knyttes til et individ er de anonyme, selv om det er en teoretisk mulighet for bakveisidentifisering (28). Store databaser, for eksempel i Beacon-nettverket, kan innrettes slik at risikoen for reidentifisering er lav, blant annet gjennom hvordan genetiske varianter og andre data gjøres tilgjengelig. Grensen mellom anonyme og identifiserbare genetiske data er dynamisk, og ikke mekanisk.
Med fremtidens teknologiske mulighetsrom kan mulighetene for å definere helsedata og genetiske data som anonyme bli mer begrenset. I en anonymitetsvurdering er det i all hovedsak dagens risiko ved anvendelse av hjelpemidler som faktisk er mulig å vurdere, selv om det skal tas høyde for påregnelig teknologisk utvikling. Mulighetene som følger med fremtidig teknologi må vurderes kontinuerlig i lys av hvordan data lagres over tid, det vil si sikkerhetsvurderinger på bakgrunn av sannsynlige trusler mot de lagrede dataene (29).
Ved usikkerhet om risikoen for identifisering vil et relevant forsiktighetshensyn være å vurdere konsekvenser av at dataene behandles som personopplysninger og av at opplysningene ikke behandles. Det omfatter vurderinger av forholdsmessighet og forsvarlighet av at genetiske opplysninger deles, for eksempel for å kunne gi medisinsk behandling ved en sjelden tilstand (30).
Usikkerhet knyttet til anonymitet kan føre til at det legges uheldige og utilsiktede restriksjoner på deling av medisinsk kunnskap. I «gråsoner» er det nødvendig å vurdere risiko i et bredere perspektiv. Risikoen for identifisering må ses i sammenheng med risikoen ved ikke å behandle opplysningene (31). Dagens samtykkeordninger er ikke tilpasset behovene for data i helsehjelpen, eller mulighetene for å oppfylle pasientrettigheter (32). Innføring av persontilpasset medisin, kunstig intelligens og big data, bør føre til utvikling av nye lovbestemte ordninger for deling av data, og samtykkeordninger. Teknologiutviklingen og forbudet i GDPR art. 9 (1) forutsetter flere lovgrunnlag for behandling av opplysninger som er omfattet av legaldefinisjonene.
Av Anne Kjersti Befring og Oda Bakken, august 2019
Full versjon av artikkelen er publisert i boken "Kunstig Intelligens og Big Data i helsesektoren": https://www.gyldendal.no/faglitteratur/jus/juridiske-fag/kunstig-intelligens-og-big-data-i-helsesektoren/p-825763-no/
--------------------------------------------------------------------------------------------------
(1) Befring/Bakken (2019). Data og opplysninger benyttes synonymt da begge begrepene benyttes i de rettslige reguleringene.
(2) Antallet frekvenser av varianten.
(3) British Medical Bulletin, «Genomic medicine and data sharing» Volume 123, 1 September 2017, side 35–45 (https://academic.oup.com/bmb/article/123/1/35/4080201)
(4) De fleste varianter sorteres bort, for eksempel fjernes varianter med høy allelfrekvens.
(5) Se https://www.ncbi.nlm.nih.gov/grc 6 The Human Genome Project. https://www.genome.gov/human-genome-project
(7) Hele det humane genom ble første gang kartlagt i begynnelsen av 2000-tallet i prosjektet: The Human Genom Project, se Befring (2019) kap. 3.
(8) Den vanligste typen genetisk variasjon blant mennesker kalles single nucleotide polymorphisms, SNPs («snips») hvor en av basene (A,G,C eller T) er byttet ut med en annen når det sammenlignes med referansegenomet.
(9) Et eksempel på feilbehandling er omtalt i Befring (2019) kap. 8.3.
(10) Befring (2019) kap. 4.4. Epigenetikken dreier seg om evolusjonen av genetikken i samspill med omgivelsene.
(11) Wright (2019).
(12) Prop. 56 LS (2017-2018) kap. 32.1.
(13) Helsepersonelloven av 2. juli 1999 nr. 64 (hpl) § 21. Befring (2019) kap. 12.
(14) Personopplysningsloven av 15. juni 2018 nr. 38. Personvernforordningen (The General Data Protection Regulation (GDPR), EU 2016/678.
(15) Pasientjournalloven av 20. juni 2014 nr. 42 (pjl.). Helseregisterloven av 20. juni 2014 nr. 43 (hregl.).
(16) Pasient – og brukerrettighetsloven av 2. juli 1999 nr. 63 (pbrl.), spesialisthelsetjenesteloven av 2. juli 1999 nr. 61 (shl.), helseforskningsloven av 20. juni 2008 nr. 44 (hforskl.) og helseregisterloven av 20. juni 2014 nr. 43 (hregl.).
(17) Se feks pbrl. §§ 1-1 og 4-1.
(18) Se hpl. §§ 4, 16, 21 og helseforskningsloven § 5.I Befring (2019) kap. 8.2 og 8.3 er dette diskutert, blant annet på bakgrunn av en avgjørelse fra Fylkesmannen i Oslo og Akershus, og brev til Oslo Universitetssykehus, datert 22.mai 2018.
(19) Befring (2019) kap. 13. 20 Menneskerettsloven av 21. mai 1999 nr. 30 § 3 jf. § 2. 21 Europarådets biomedisinkonvensjon/Ovideo-konvensjon av 1997.
(22) NEM (2016) s. 7-8. Helsedirektoratet (2016) s. 61-62. 23 Brev fra Helsedirektoratet til Helse- og omsorgsdepartementet datert 28. november 2017 GDPR Hpl. og Hpl. og Hpl. og Hpl. og pbrl. Pjl. og shl. Pjl. og shl. Pjl. og shl. Hfl. og Hfl. og hregl. hregl. Pol. Pol.
(24) Wright (2019).
(25) Shabani og Marelli (2019).
(26) Momenter i vurderingen kan utledes av fortalepunkt 26 til GDPR og juridisk teori.
(27) Helse- og omsorgsdepartementet (2019) s. 14.
(28) Helsedirektoratet (2016). Befring (2019) kap. 13.
(29) Befring (2019) kap. 12.5.2
(30) Befring (2019 kap. 8.3.
(31) Både forholdsmessighetsvurderinger og forsvarlighetsvurderinger kan få betydning i denne situasjonen. Samtykkeordningen kan i mange situasjoner være for begrenset, noe som kan illustreres med at et samtykkekrav kan begrense grunnleggende pasientrettigheter, for eksempel til å kunne motta helsehjelp uavhengig av evnen til å samtykke, til å beskytte seg mot informasjon og til å benytte data for å stille diagnoser når personenes identitet er tilstrekkelig beskyttet.
(32) Samtykkeordningen ivaretar for eksempel ikke pasienter og forsøkspersoner som ønsker å bidra med helseopplysninger uten å være i interaksjon slik et dynamisk samtykke legger opp til- .


