I dag er det er mange forskere som behøver hurtig tilgang til automatiske og oppdaterte uttrekk av pasientdata fra journalsystemer for å bearbeide og analysere data, samt bruke de til forskning og utvikling av diverse støttesystemer for klinikerne basert på NLP og kunstig intelligens (KI). Hvordan kan en prosess for automatiske uttrekk av pasientdata fra et elektronisk journalsystem konstrueres slik at dataene automatisk anonymiseres og flyttes til en sikker forskningssone hvor forskerne kan jobbe videre?
Dagens journalsystemer med pasientdata ligger i produksjonssoner hvor tilgangen er begrenset kun til IT-forvalteren. Samtidig gjør reguleringer i lovverket det forbudt å forske på produksjonsdata hvor samtykke ikke er innhentet og hvor data ikke er anonymisert. Forskningsaktivitet skal bedrives i egne sikre soner godkjent og tilrettelagt for dette formålet.
Løsning
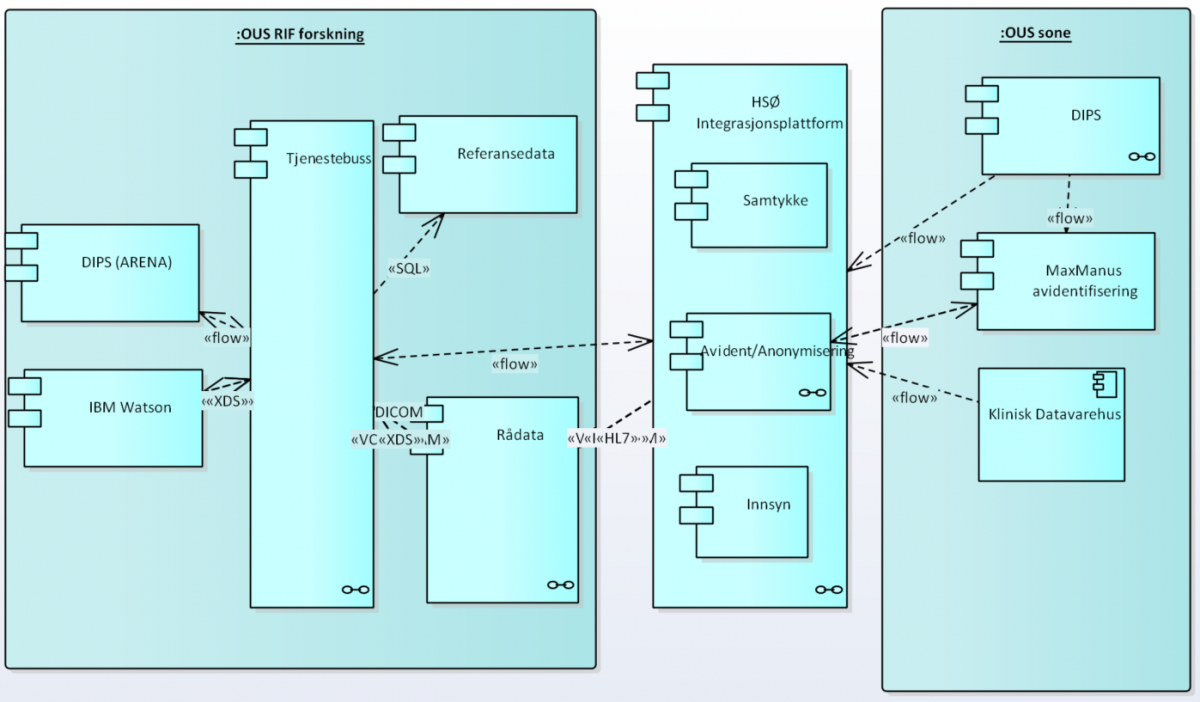
BigMed har jobbet med hvordan en slik prosess kan se ut for automatisk å flytte data fra en produksjonssone over til en forskningssone, samtidig som pasientdataene automatisk anonymiseres i prosessen.
Løsningen ligger i å bruke komponenter som trekker ut data
fra journalsystemet på en produksjonsslik sone, slik at produksjonen ikke forstyrres ved store datauttrekk. Deretter brukes standard komponenter for å anonymisere dataene og det benyttes eksisterende transportmekanismer
for automatisk å flytte de nå anonymiserte dataene over til en avgrenset forskningssone hvor data kan bearbeides fritt.
Bildet under illustrerer to soner (produksjonslikt til høyre og forskningssone til venstre), samt transportmekanismen (i midten) som automatisk flytter data mellom sonene.