A risk calculator which aids in patient risk estimation for Sudden Cardiac Death (SCD) has been published by the European Association of Cardiology, and the BigMed cardiology work package has been tasked with automating and if possible improving the risk prediction for this patient population. Naturally, the overall aim is to broaden the scope to include other patients at risk.
Barriers to automatic and improved risk estimation
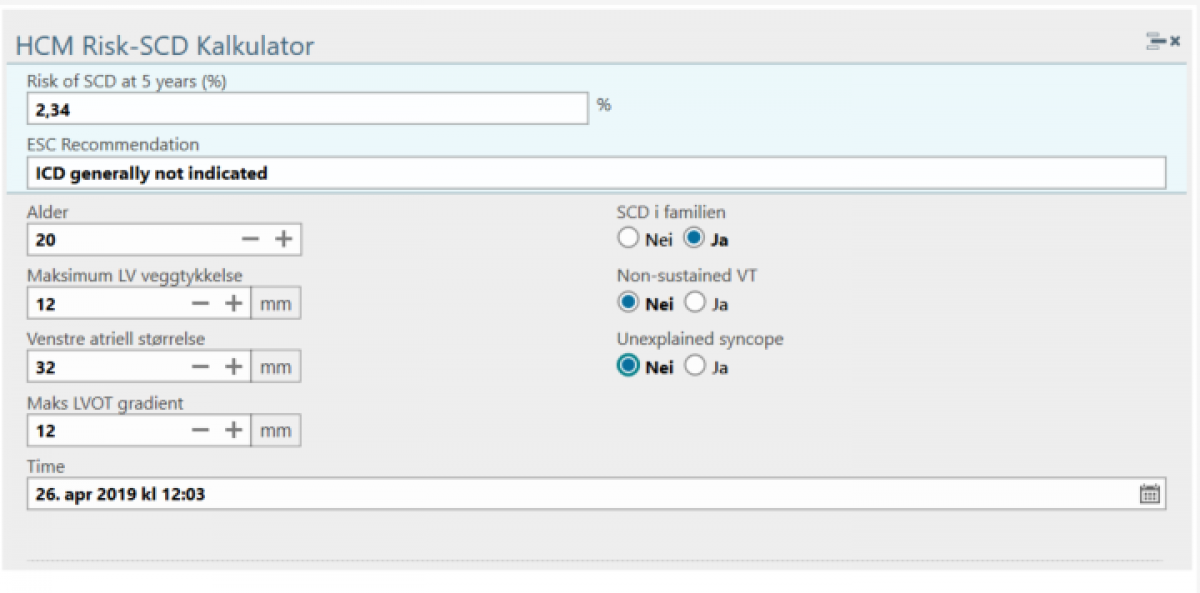
The elements in the current HCM SCD risk
calculator are a combination of echocardiographic measurements, anthropometric
and disease history data. While some of the data points exist in structured
form, several are buried in the narrative of the patients’ electronic health records (EHR), and
even the structured data are not preserved in a form that is re-usable in a later
process. Below we discuss some of the barriers to automation and re-use of data
identified in the project, and the associated subtasks.
Natural language Processing
Family history is part of several disease risk scores, and mapping familial phenotypes is also useful in the diagnostic process when a genetic component is suspected. In the EHR, family history exists as unstructured narrative text, and identification of risk factors is a manual task.
In order to employ contemporary natural
language processing (NLP) methods in the analysis of EHR records, large
corpuses of text are needed. The current health care and research systems are not set
up to handle a request for NLP analysis of large amounts of records. In order
to adhere to strict information security and privacy provisions, BigMed is designing a new infrastructure platform, including a consent/waiver
gateway, and de-identification solutions to remove personal identifiers from
narrative text.
Alongside the process of infrastructure design and implementation, we have demonstrated the utility of synthetic data use in developing NLP annotation guidelines (https://www.aclweb.org/anthology/W18-5613/), and in a follow-up study demonstrated the ability of models trained on synthetic data to extract useful family history information from actual clinical notes (JBMS 2019, in review).
Syncope (loss of consciousness) is a
risk factor in both HCM and other cardiac diseases. The health record code for
syncope according to the international classification of diseases (ICD-10) is
R55, and the presence of such a diagnostic code in the patient record has been
shown to be highly specific. The sensitivity, however, is low. From a large
Danish study, approximately 1/3 of patients admitted to hospital with a syncope
did not receive the R55 ICD code. Consequently,
a more sensitive marker is needed to automate risk prediction.
Collaborating with Akershus University
Hospital, we are currently developing NLP tools to identify patients with
syncope.
Preservation and precision of measurements
Echocardiography (ultrasound of the heart) is a central tool in cardiology, and measurements and observations from the exam are key in diagnosis, treatment planning and risk prediction. In the HCM risk calculator example, several standard echo measurements are required.
While current hospital ICT solutions partially preserve echo measurements in a digital form, they are presented and stored in a human-readable form in the EHR, rather than transferring the analysis as a key-value pair from the echo analysis software to the EHR. A human-readable version is obviously necessary for daily clinical use, but for big data solutions and automatic decision support applications, structured data that allows downstream use is needed.
As part of the BigMed project, we are implementing a solution for echo measurement preservation and transfer to the hospital clinical data storage, and further on to an infrastructure platform to be analysed.
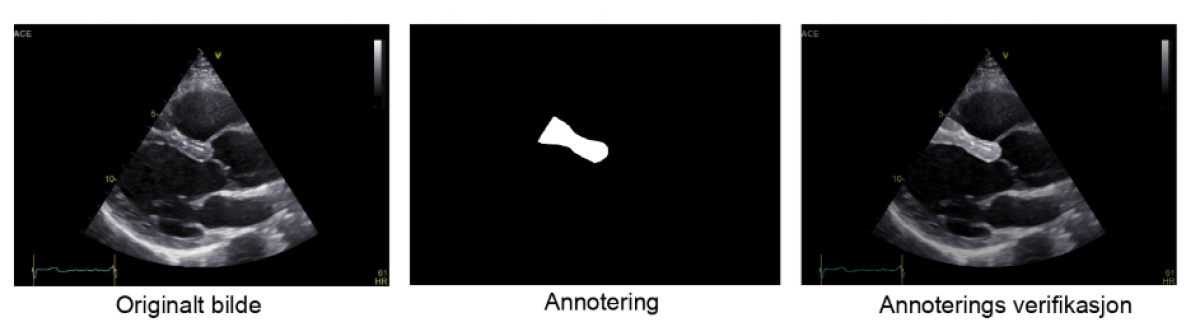
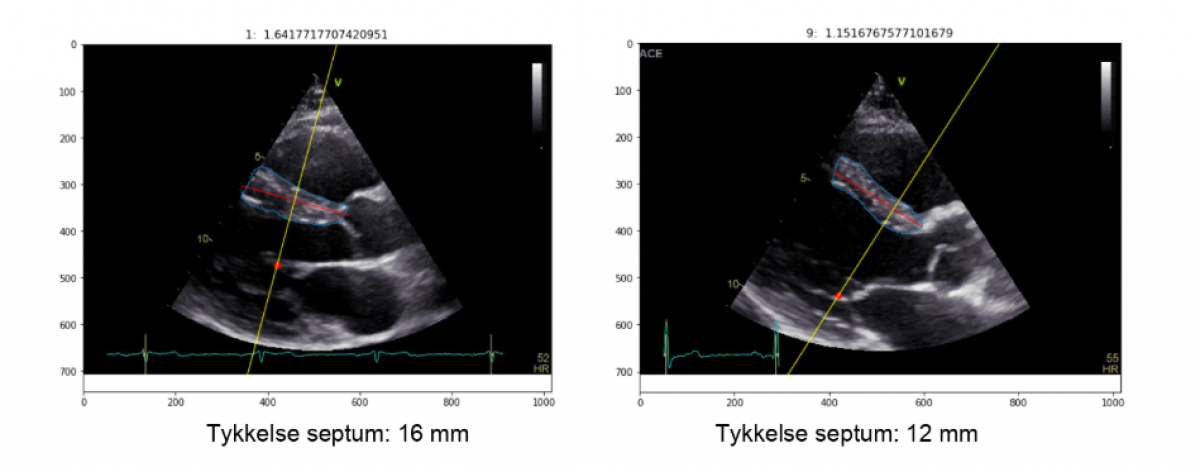
Manual echocardiographic measurements have a high intra- and inter-observer variability, and the variables incorporated in current HCM treatment guidelines are not always measured or reported. In order to address the availability, reproducibility and precision of echocardiographical markers of risk, we have performed a pilot study of machine learning methods for automating measurements of interventricular septum thickness in collaboration with consulting company Inmeta.
In the pilot study, echo scans of a small number of healthy volunteers were used to train a convolutional neural network to recognize and measure the part of the echo image representing the intraventricular wall. Standard data augmentation techniques were used to increase the available training data set from 50 to 5000 frames.